

In today’s data-driven world, understanding and leveraging data effectively can transform how we approach various challenges. One powerful technique in the realm of data science and machine learning is K-means clustering. This is the algorithm behind Acorn, CACI’s flagship data product which groups together postcodes with similar characteristics into segments. Whilst this process can all be done fairly easily with modern ML techniques, one crucial component is often overlooked: human interpretability.
What is K-means clustering in the context of Acorn?
K-means clustering is an unsupervised machine learning algorithm used to group data points into clusters based on their features. The goal is to minimize the variance within each cluster and maximize the variance between different clusters. To demonstrate how this is done in practice, the following steps are used in the build of Acorn, although the same process will broadly apply to any K-means algorithm:
The need for human interpretability
This process looks like it requires very little intervention from a human at any point – and that’s because it doesn’t – in theory. However, in practice as with all unsupervised ML techniques, for Acorn to be of any use as a segmentation tool, information must be scrutinised at every step along the way.
First, the number of clusters must be chosen either randomly or with prior domain knowledge. Acorn has been around for nearly 50 years and the last iteration featured 5 marketable segments, making it a good starting point. However, after stakeholder input from across the business, a conscious choice was made to increase the number of groups to 6 to reflect changes in society since the previous build.
Next, input variables need to be decided on before the clustering process begins. With a wealth of data from the 2021 Census as well as newly available information such as disposable income data, this list of variables needed to be carefully refined for Acorn to be both a mathematically and commercially sound product. As an example, the inclusion of planning extension data was tested as a promising new input to highlight areas undergoing gentrification. However, the results from this didn’t make intuitive sense and so this variable was excluded from the model. Such conscious decisions were also made to ensure that Acorn is fully compliant with the UK Equality Act and exemplify the need for human input before even running a model.
With the input variables decided on, K-means clustering can be applied, but the element of human input does not end here; the segment outputs must be dissected to ensure they are dissimilar from each other and contain an acceptable minimum number of data points. In the context of Acorn, this meant looking at the number of postcodes in a segment and measuring average values for the input driver variables. For example, averages for percentage of houses that are detached and household income were measured for each segment. These figures were found to be highest for groups containing individuals more likely to be in managerial roles, which acted as a useful sense check and allowed such groups to be labelled as more affluent. The number of postcodes within each group also needed to be sufficiently large to allow different marketing strategies to be applied for each segment.
Postcodes were also analysed visually on a 2D scale using a Python package to identify overlaps between segments. The difference between the old and new versions of Acorn can be seen below.
Figure 1: A representation of old (left) and new (right) Acorn postcodes drawn down from a multidimensional space to a 2D visual, with each colour representing an Acorn segment.
The reduced ‘bleed’ of segments into other segments as seen from this visual made it clear to analysts that this newer version of Acorn has much more well defined segments – a result of new data, advanced ML capabilities and of course, stakeholder input.
Finally, and arguably most importantly, the ultimate question must be answered: will the outputs of the model be valuable to the end user? If the answer is not a definite yes, then the process needs to be reviewed and, more often than not, this will involve decisions around the human element of the process rather than consulting the ever-growing list of ML techniques and tweaks. To increase the value of Acorn for clients across sectors including retail, finance, charities and utilities, questions from survey partners were mapped onto Acorn to provide insights such as digital attitudes and channel preference by segment. These questions are updated on an annual basis based on stakeholder feedback to ensure questions are current and relevant to clients.
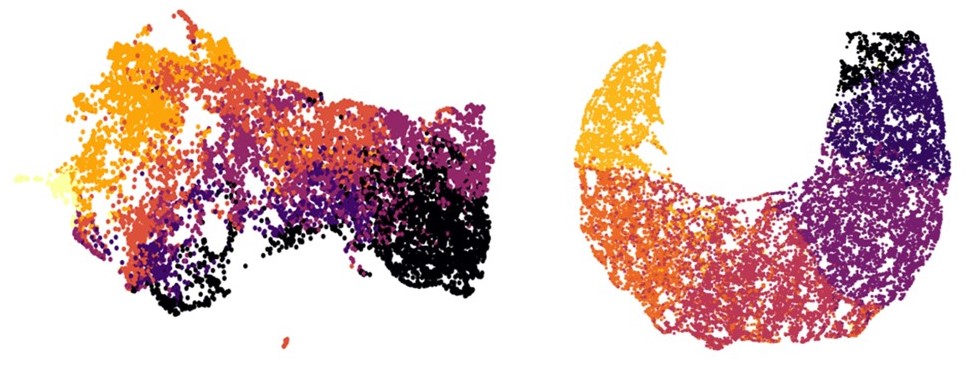
Conclusion
Ultimately, results need to be useful for individuals or teams and there is currently no way of achieving this without human interpretation and intervention to some degree at every stage of the process. This rings even more true in consumer segmentations, where there is no ground truth or right or wrong to compare to. Lots of packages will allow you to build a model with very little input or intervention, especially with the rise in autoML capabilities, but to build a trustworthy, useful product, humans need to be on hand at every step along the way.