In any competitive market, being proactive can make all the difference. For example, developing new application features that make your processes more efficient can save time and free your team to focus on more challenging tasks.
Change isn’t easy if you’re going it alone. You need the right processes and skills in place from the off. While this isn’t impossible to achieve, it doesn’t happen overnight. Even for the best organisations, it can take time, effort, and significant resources.
There is another way: working with the right partner with the right expertise to help you drive meaningful change.
At CACI, we’ve spent decades helping clients navigate and pre-empt shifting markets. Here are three ways we’ve helped them to be more proactive.
#1 – ELIMINATING COMPLEXITY AND MANUAL DATA ENTRY
While it can be tempting to stick with the old ways of doing things, this will almost certainly breed unnecessary complexity and manual processes.
Take a crowded public place for example. One of our clients is required by health and safety law to monitor and record footfall. It’s a critical part of the company’s understanding of congestion at its sites – and how it can make changes to reduce it.
But when the standard method of recording this information was pen and paper, submitted periodically, our client found that its staff were spending so much time filling out paperwork that they struggled to carry out their other daily routines.
Our solution was simple: a digital app that replaced paper forms and allowed staff to upload a variety of supporting documents – removing tedious, manual data entry, and freeing valuable people to focus on other tasks.
#2 – USING TECHNOLOGY TO SOLVE CRITICAL PROBLEMS
In healthcare, preventative treatment can catch potential issues before they become bigger problems, helping people live healthier lives. What’s more, a healthier population means less pressure on the NHS and more evenly distributed budgets.
University College London Hospitals NHS Foundations Trust (UCLH) identified that without appropriate screening, some of the most vulnerable groups in the UK were at risk of contracting TB – a disease which can be a significant challenge to treat if not discovered in its early stages.
So we worked closely with UCLH to develop its internet tele-radiology information and communication system (ITRICS), which helps to identify, manage, support, and treat patients while they wait (a particular advantage for those without fixed addresses who are hard to track down).
By identifying cases more quickly and with greater accuracy, UCLH is now able to provide effective treatment on the spot. This reduces the pressure on its outreach teams and helping them serve more people when they need it most.
Bringing new applications to market quickly is not just helpful in healthcare. It’s also helped Waitrose & Partners deliver a more seamless customer shopping experience.
We worked together to consolidate the retailer’s multi-device ecosystem – including providing comprehensive ongoing device support – and now it’s easy for Waitrose to develop a wide range of applications for any customer mobile device.
#3 – ANTICIPATING ISSUES TO HELP MITIGATE THEIR IMPACT
Understanding upcoming changes that could impact your operations – and taking proactive action to mitigate those effects in advance – can help you avoid potential problems and stay ahead of the competition.
In the retail sector, a sudden change to something seemingly straightforward, like the VAT rate, could have huge legal implications, literally overnight. And we helped Waitrose & Partners to prepare for exactly this.
Changing product prices to reflect a tax change sounds simple in theory, but the reality is hundreds of thousands of products that each need updating at once – with no room for error.
That’s where batch processing comes in. By making these price changes in sensibly sized batches (usually overnight to limit point-of-sale disruption), our client avoided painful database errors that could have risked non-compliance and customer dissatisfaction.
We also helped Waitrose & Partners to prepare for the food import challenges posed by Brexit. By using stock smoothing techniques where the locations of the most buying were analysed and supplied accordingly, the retailer has been able to reduce the impact of perishable food disruption – and it now uses the same technique to deal with adverse weather events that threaten suppliers both at home and abroad.
PROACTIVE CHANGES, COUNTLESS BENEFITS
Often, change is out of our control. But what we can do is be proactive about how we prepare for it – so we’re ready when it happens.
What’s more, being proactive can also help you be more innovative and responsive to your customers’ needs – opening critical revenue-generating opportunities for you.
In the next blog in this series, I’ll focus on a tactic many of our clients use to optimise their processes and technology. I’ll also look at how they hone their ability to execute test and learn programmes.
According to research by BCG, 70% of digital transformation programmes fall short of their objectives. One reason for this is that organisations often see technology as a ‘silver bullet’ – and end up creating more problems than they set out to solve.
That’s why it’s essential to know exactly what factors should help you drive change. And who better to learn from than some of the UK’s top brands?
We took the opportunity to look at some of our clients’ most successful digital transformation challenges. And we found three key strategies that have helped shape their success over the past year.
#1 – LISTEN TO YOUR CUSTOMERS – THEY USUALLY HAVE THE ANSWER
Customer demands are one of the biggest driving forces behind changing industry trends.
Responding to those demands effectively is critical. Failing to meet them can reduce customer satisfaction, and you risk losing customers to competitors who are offering what they want.
At the very least, you might miss out on new revenue opportunities that, if executed correctly, could accelerate your organisation’s growth and brand reputation.
Our relationship with UK hospitality giant Mitchells & Butlers has always centred around meeting changing customer demands. We helped them to introduce innovative new applications to serve their customers better.
For example, we worked closely with the client’s own team to develop an order-at-table app that delivered both real-time item availability and flexibility for their customers at each stage of ordering. It is a simple, straightforward solution putting customers in control.
#2 – TAKE A PROACTIVE APPROACH – BUT BE PREPARED TO REACT
Understanding your customers – and market trends – goes a long way to helping you take a more proactive approach.
For a long time, we have been helping Waitrose & Partners to adapt to more of its business moving online, and to deliver the exceptional experiences its loyal customers expect across a wider range of channels.
But when the COVID-19 pandemic hit, few could have predicted the knock-on effects of a nationwide lockdown on customer habits. When retailers were hit with sudden panic buying, they had to react fast.
For Waitrose & Partners, this meant putting controls in place to ensure its customers could still buy the wide range of products they expect, while also limiting the nationwide impact on supermarket essentials.
Together, we applied product capping techniques to limit bulk buying. By using volume testing to introduce sensible limits on key products, and stopping promotions in line with trading standards law (while starting new ones on uncapped products), the retailer ensured its customers could get what they needed, still safe in the knowledge there were offers to be had.
Once we were confident panic buying was under control, we made changes to stock control systems to help spread the supply of in-demand products across all sites.
Meanwhile, we were also working with the retailer on its Brexit planning contingencies – helping to ensure perishable product disruption is kept to a minimum by adapting sources to within the UK or unaffected countries.
The number of online orders retailers receive is increasing year on year. So, being able to scale as and when you need to is critical. While some peak trading periods – such as Easter, Black Friday, and Christmas – can be plotted on a calendar and are relatively easy to plan for, what happens when the retail landscape changes overnight?
This was the problem faced by Argos when the COVID-19 pandemic hit. While nationwide lockdown restrictions forced its physical stores to close, its online and click-and-collect orders surged to around 90% of its total sales – putting huge pressure on its digital infrastructure.
We’ve been working with Argos for decades, so both teams knew what was required to help the company adapt. Our programme of works took shape in two phases. The first was at store level, where we shifted the focus to optimising stock and picking systems for home delivery and enabling items to be ready for click and collect. This allowed Argos to keep stock disruption to a minimum.
We then worked with the company’s development team to streamline its nationwide distribution network and accelerate system testing – helping Argos to sustainably manage stock around its sites in the long term.
TAKE A CHALLENGE-LED APPROACH TO DIGITAL CHANGE
These examples show how with the right approach – and the right partner – you can unlock new levels of digital change to improve your customer experience and foster further innovation in turn.
By taking a consultative approach that strikes the right balance between making proactive changes and reacting to customer demands, you can make better decisions that will help you maintain a competitive edge.
If you’d like to explore the topic of proactivity a little further, you’re in luck. Read the next blog in the series to discover three ways our clients turned their biggest challenges into their biggest proactive opportunities.
Over the past months, we’ve all had to adapt to home working and rapidly equip teams with the tools they need to continue operating as normal. This quick shift has forced organisations to adopt new systems and services, from cloud storage platforms to file sharing tools, to keep teams connected and offer easy access to the data they need.
But in many cases, the pace of change has been prioritised over data protection. Some organisations are now left without a clear view of their security profile – creating rich opportunities for fraudsters. That’s why it’s critical you have a clear view of where your data is, how it’s being used, and who’s using it at all times of the day.
Don’t panic though; filling these data security gaps doesn’t need to be difficult. In this blog post, I’ll ask three important questions about your data. Answering them will help identify some easy ways to strengthen your security profile and keep your data safe.
QUESTION #1 – DO YOU KNOW WHERE YOUR DATA IS?
Even before the shift to home working in 2020, it’s likely you were either already using cloud services, or in the process of migrating some of your key resources to one. It’s a great way to lower your costs, improve collaboration across your teams, and give employees access from remote locations. But while cloud platforms provide plenty of benefits, there are a few security risks to look out for.
With many cloud platforms, it’s not always clear where your data is physically being stored, or how it’s being used. Even if you’re accessing your cloud service from the UK, many software-as-a-service (SaaS) and cloud storage providers rely on international data transfers and remote data centres to store and manage your data. And if you’re an organisation that handles sensitive data that’s bound by tight regulations, this process can create some major challenges.
When considering a SaaS or cloud provider, look closely at their data sovereignty policies, and ensure you have a clear understanding of where your data is being managed. The big three cloud storage providers – Google, Microsoft, and Amazon – all have data centres across the globe to solve this issue, and often let you choose exactly where you want your data to be kept.
Alternatively, if your organisation has specific sensitive data sets that can’t be stored on a cloud platform, you could use a hybrid cloud model to gain greater control over how your data is stored managed.
QUESTION #2 – WHAT DEVICES ARE ACCESSING YOUR DATA?
When you sent your employees to work from home, you may not have had the budget to equip everyone with new laptops and mobile devices. And that’s okay – many organisations encourage people to use their own devices for working; it saves additional costs and improves convenience for employees. But if you’re taking this approach, it’s important you have strong, standardised security measures in place.
Using personal devices can create new data security risks that might not be immediately clear. For example, most employees will be the system administrator of their own device – whether it’s their home computer or their mobile phone – which means your technology team has limited control over their security settings. If just one person’s device is compromised, it could offer direct access to data and company infrastructure.
And it’s not just digital security you need to consider – it’s the physical security of those devices too. With employees spread across different locations, it can be difficult to know who has access to their devices. In most cases it’s likely just family members, but in a worst-case scenario, it could be a thief looking to gain access to your data.
Our advice:
Overcoming risks related to personal devices is easier when you have strong endpoint security measures in place. These can often be as simple as making regular, automatic endpoint health checks using a dedicated security solution, or sometimes even native cloud platform features.
It’s also a good idea to take the time to educate your employees around common threats like phishing attacks, to ensure they can identify them when they happen, and avoid compromising the rest of your company.
QUESTION #3 – HOW ARE YOUR PEOPLE ACCESSING
YOUR DATA?
In most modern workplaces – from schools to investment banks – employees need to transfer files to each other, access shared data, and even collaborate on the same documents. When all your teams are in the office, it’s easy to connect everyone through your company’s network – but at home, it’s a new challenge.
Many businesses have turned to virtual private networks (VPNs) for a quick, user-friendly way to connect employees from remote locations as if they’re working in the office. It’s a convenient solution, but it also comes with the compromises of reduced defence against malware, limited control over employee devices, and a lack of protective resources.
In other cases, employees may have adopted their own methods of file sharing. Popular tools like WhatsApp messaging and email are all handy for sharing low-risk documents in our personal lives, but they can’t offer the robust security measures needed for handling sensitive data.
Our advice:
To prevent employees taking file sharing into their own hands, you need to ensure you’ve got a secure, reliable, and easy way for employees to access and share data.
That might be a robust cloud platform that enables real-time document collaboration and secure data storage, or through your existing infrastructure using dedicated security measures to protect transfers.
STRENGTHEN YOUR REMOTE WORKING SECURITY PROFILE
Data management is just one half of what it takes to create a strong remote working security profile.
Rust has quickly become one of my favourite programming languages with its brilliant tooling and rich type system. In recent times, its community has been working towards making it a language for the web, both on the server and in the browser.
As a systems language that may be a bit of a surprise. But how can it run in a browser? Enter WebAssembly.
WebAssembly (wasm) is a nascent technology initially aimed at providing an assembly language and runtime environment for web browsers. This has since been broadened to a portable assembly and runtime, not just the web, with several efforts in creating portable runtimes (wasmtime, Lucet, wasm-micro-runtime, waSCC, et al) with host system interfaces (WASI). This evaluation is however limited to running rust compiled to wasm in the browser.
Wasm enables code written in languages that usually target native platforms (such as C, C++, Go & Rust) to be compiled to portable bytecode like Java or C#. In web browsers, this bytecode is executed in a sandbox environment entirely within the JavaScript VM. Wasm modules can be loaded and invoked from JavaScript and JavaScript code can be invoked from wasm modules, though there are currently some limitations with tooling that make some of this difficult (see below).
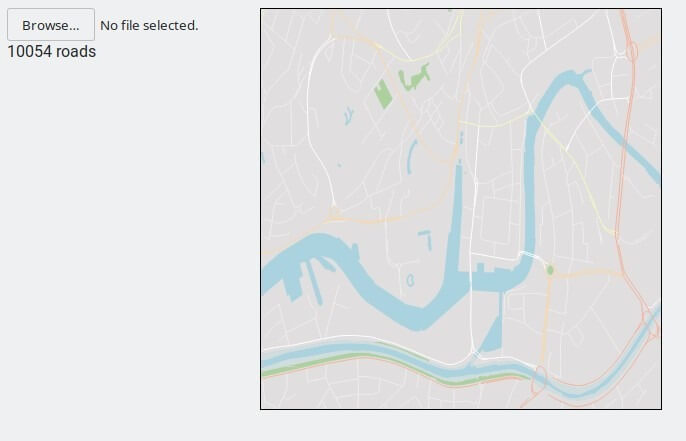
As a proof of concept, a few months ago I created a very basic map drawing application written mostly in Rust. It takes OpenStreetMap data as input and plots and draws this on a canvas element, producing a line-drawn map of the area including roads and some natural features.
Here’s how part of central Bristol looks:
The map can be zoomed in or out by scrolling within the area and it can be clicked and dragged to move it around. This basic functionality is responsive on my machine at least. The coordinates to plot are calculated in advance and kept in memory as I found this to have the best performance overall once more things were being drawn.
Using the canvas to draw, scale and translate resulted in jittery dragging and poor-quality scaling. I didn’t have any success with drawing to a canvas offscreen and then loading this to the onscreen canvas. OffscreenCanvas is only partially supported in Firefox so I didn’t get very far with that, but I also couldn’t get CanvasRenderingContext2D to work offscreen either.
This has all been a learning experience and I’m sure I’ve made some (probably obvious) mistakes. Much of what has been done resulted from workarounds of individual issues that I could see being done differently now. Anyway, here is an account of my experience with it based on how things were earlier this year – there may have been improvements made to the language over the last few months.
JAVASCRIPT + RUST
The Rust WebAssembly working group has provided some tools for working with this. Rust code targeting wasm can call JS code easily through bindings generated by the wasm-bindgen tool and library. This is typically used to annotate Rust code to export bindings to JS (generates equivalent-ish code and glue), or annotate ffi declarations to import JS code. The wasm-pack tool is used for doing all the steps required for compiling Rust to wasm, generating JS glue code, and packaging it all up, invoking wasm-bindgen as necessary.
Many Rust crates (libraries from crates.io) can be compiled to wasm and so can simply be added to your project’s Cargo.toml as a dependency, although there are some limitations to this (see below).
EXPORT TO JS
Rust structs are exported as classes to JS when marked with #[wasm_bindgen]. Since Rust doesn’t have constructors, an associated function can be marked with #[wasm_bindgen(constructor)] to be exposed as a constructor so that a class can be instantiated with new Example(data) in JS (see image below). There are all sorts of variations on this that can be seen in the wasm-bindgen docs.
IMPORT FROM JS
JavaScript functions can be called from rust through the use of bindings.
Snippets
Import from a snippet packaged beside Rust code (see image below). Note that the wasm-bindgen tool is not currently capable of allowing module imports within the snippets imported this way.
JAVASCRIPT AND WEB APIS
Built-in JS types and APIs are exposed to Rust with the js-sys crate. Web APIs are exposed in the web-sys crate, using js-sys where necessary. Both of these crates are fairly low-level bindings only and aren’t always easy to use from Rust or at least aren’t idiomatic.
Notable features:
web-sys contains bindings for everything I’ve tried
JS-style inheritance maps quite well to Rust (which has no inheritance)
Deref trait is used such that a type may be “dereferenced” automatically to its parent type where necessary, similarly to how smart pointers get dereferenced
Typical issues:
data type conversion to JsValue
often via JSON strings for non-primitives
every data type in web-sys is behind feature flags
great for generated code size
less great when you have to keep adding flags to the build for every little thing
makes auto-complete not work(!!)
wrapping closures is cumbersome
overloaded JS functions have to be separate in Rust
eg. CanvasRenderingContext2D.createImageData() in JS is create_image_data_with_imagedata and create_image_data_with_sw_and_sh in Rust for each overload
not an issue exactly, but there isn’t much integration with rust’s mutability and ownership model
everything is &self even though state may clearly be modified
stdweb
Interestingly there is also the stdweb crate. Whereas web-sys aims to provide raw bindings to the Web APIs, std-web aims to bring more idiomatic Rust APIs and doesn’t utilise web-sys at all. I opted to stick with plain web-sys for a couple of reasons: stdweb doesn’t have IndexedDB support so I had to use web-sys anyway, and web-sys is the official Rust wasm library for this, and there isn’t interoperability between these. This situation may change in the future and I did read some comments from the author that hint at basing stdweb on top of web-sys.
LIMITATIONS
Crates
Many crates are written under the assumption that they will be used in a proper operating system environment, not a web browser sandbox. IO (emscripten manages with emulation, why not Rust?), processes, multi-threading (there is some experimental support using Web Workers) are among the things that will fail at runtime with wasm compiled rust code. This was pretty frustrating. I would add a dependency and write code to integrate it, only to have it fail at runtime because it parallelised some computation, or read from or wrote to a file for example.
I believe a better approach given the current status of tooling would be to use a webpack with a wasm-pack plugin and some other plugin to generate a Rust crate from an npm package, rather than use wasm-pack directly. This hasn’t yet been explored but I’ve seen at least one example somewhere that does something like this.
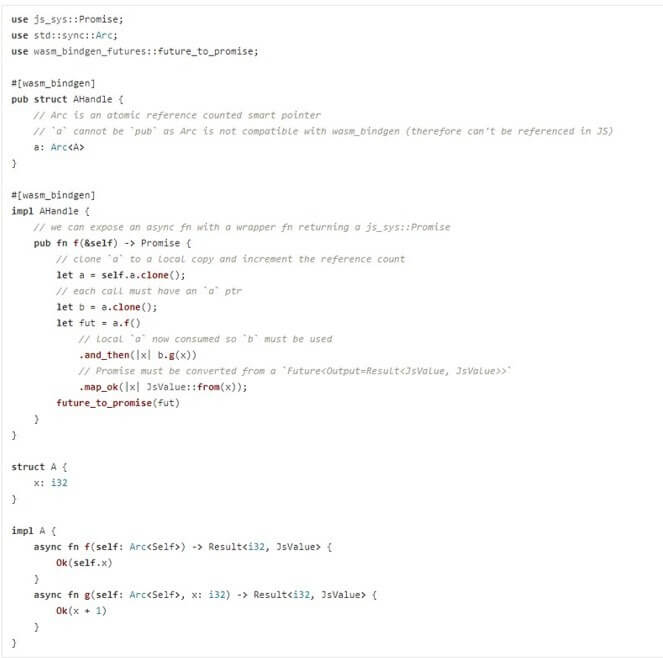
Asynchronous functions in Rust have recently been stabilised using futures as the building blocks. This works well and even integrates with JS using Promises, thus opening the door to interfacing with asynchronous Web APIs in a natural way. The main problem I faced was that to use async methods, I had to have this method consume self not take by reference due to Rust’s borrow checker (even though most of the time these functions were fine when not marked #[wasm_bindgen]). This is OK for one-off function calls for one-off objects, but once this function is called, the object cannot be used again. Rust side gives compile time error. JS side the pointer is nulled and a runtime error saying “a null pointer was passed to Rust” will be given.
The best method I’ve found so far for dealing with this is shown in the image below – where A is the struct with the async function(s) to expose. This is far from ideal, but it’s mostly the result of exposing these async functions to JS. I’m certain there are better solutions to this.
IndexedDB
IndexedDB is a browser-based NoSQL database with a JavaScript API. This has been used to store OpenStreetMap data in a lightly transformed state, which the application then reads on load to feed the map plotting. This works well and IndexedDB is promising for offline storage, though I’ve not explored some of its actual database features, namely indexes and queries. Since this is browser technology it is available to any language that can access browser APIs.
IndexedDB has a completely asynchronous API but pre-dates Promises and is quite awkward in JavaScript, let alone Rust. A wrapper library indexeddb-rs has been used for interacting with IndexedDB, but this was incomplete (and doesn’t compile in its current state at 371853197233df50069d67f332b3aaa3b555b78c). I’ve filled in some gaps to get it to compile, upgraded to the standardised futures version, and implemented basic transaction support so that I could manipulate database structure and insert and retrieve data. My fork is a submodule in this repo in indexeddb-rs and available on gitlab. Ideally this would be contributed upstream.
I had initially used Dexie for interacting with IndexedDB but this proved too cumbersome no matter which way I tried it (binding Dexie directly in rust, creating small wrappers in JS and binding these, doing all DB work JS side and sending this over to Rust).
Pure Rust Application
I’ve found that many of the issues mentioned here stem from trying to combine JavaScript and Rust application code rather than writing all in one or the other. The official tutorial goes this route of having JavaScript driving the application so I attempted to follow. When I began I wasn’t quite sure how to make the jump to a pure Rust application given the constraints of the wasm runtime. You can define an entry point function (or simply call this entry point from JS) with some kind of application loop but dealing with state becomes quite difficult within this, particularly when you bring async functions into it (required for IndexedDB interaction). Although now async functions can be exposed as start functions so the situation has improved since this began.
Some Rust application frameworks exist that seem promising for this purpose, some taking very different approaches from each other: Seed (web front-end framework), OrbTK (multi-platform GUI toolkit with wasm support), Yew, Percy, and more. Yew seems the most mature and has some traction in the community, but it’s based on stdweb and also doesn’t integrate well with futures or async functions, instead using an actor model for concurrency. Sadly I don’t think any of these are ready for production.
Seed
Seed is a Rust front-end framework targeting WebAssembly, strongly influenced by Elm and React. It’s based on the official libraries/tools web-sys and wasm-bindgen so integration with other things is/will become easier. It also has an easy way to invoke async functions so that’s nice. Unfortunately seed is quite immature overall and gives no stability guarantees right now. Though it is quite approachable if comfortable with the Elm model.
OrbTK
OrbTK is a GUI widget toolkit aiming to be cross-platform for desktop, mobile and web applications. Whilst it’s early days it is usable already and the examples are quite understandable. What’s interesting about OrbTK is not just its platform-independence, but also that it’s backed by some quite interesting technology like an ECS (entity component system) to manage state and a FRP(functional reactive programming)-influenced API. It was very easy to compile some of the examples to target wasm and the widget-based examples run almost as well as they do as native desktop applications. The canvas example has very poor performance in browser however (looking at the code it appears to be using both a software renderer “euc” and its own bitmap renderer, not web canvas). Still clearly a long way to go for OrbTK but it’s a promising GUI framework, something which Rust is lacking.
Gloo
Another that’s worth mentioning is Gloo, also from the Rust Wasm group. Gloo is a modular toolkit to help with building web applications rather than a full application framework. Currently it has modules for events and timers, basic building blocks but a good start. Seed already uses some of Gloo and has stated it will continue to do so as it develops.
CONCLUSION
As it stands, many of the pieces are in place for WebAssembly to take off as a platform for secure and performant code execution on the web. It appears to be getting more and more popular outside of the web too, especially in cloud and serverless environments. It reminds me a bit of the JVM in some ways, just with a much lower level execution model which allows languages like C, C++, Rust and Go to target it.
For web applications, I think that Rust + Wasm is an option, with some caveats. Rust has a steep learning curve itself, but since most of this ecosystem is new or abstracting old with something new, it all has a learning curve. The Elm-like model adopted by front-end frameworks like Yew and Seed does seem to work well with the Rust way of doing things. But I couldn’t say whether it has any advantage over Elm or React with JavaScript or TypeScript, other than not having to write much or any Javascript and a different set of tooling. Rust’s strictness with ownership got in my way quite a bit, though as mentioned above I think this can largely be attributed to trying to use both JavaScript and Rust together with async functions. For offline apps, IndexedDB makes persistent data storage in-browser a breeze whether from JavaScript or WebAssembly. So really, Rust is just another language that can run in the browser. Rust itself has some great language features, but I haven’t gone into any of that here.
So in answer to the title question – not yet. But watch the space.
After an extension because of the COVID crisis, support for Drupal 7 will run out on Monday 28th November 2022. Upgrading to Drupal 9 means a full site rebuild – so end-of-life will come around quickly for owners of large or complex sites. Here are the key things you need to know.
In my 13 years as an active part of the Drupal development community, the platform has gone through at least four major versions. Usually, it’s a process of evolution – each version building on and refining the one before.
But when Drupal 7 reaches end of life in November 2022 – eleven years after release – it will be a different matter. The internet is very different today, and the platform’s fundamental architecture is changing in response.
The result is a Drupal that’s more flexible, with better mobile capabilities, and that’s easier to integrate with third-party services and content. But it does mean that sites built in Drupal 7 will need to be rebuilt.
STICKING WITH DRUPAL 7 IS NOT A REALISTIC OPTION AFTER 2022
Drupal 7 has been the framework’s longest running and most widely-used version to date – and even though Drupal 8 was released in 2015, there are plenty of websites yet to make the migration.
But persevering with Drupal 7 after 2022 is not a viable option for most major sites. End-of-life means Drupal 7 won’t receive any of the system’s new features or capabilities. Most importantly, there will be no new security updates – which means sites built in Drupal 7 will become increasingly vulnerable to attack. In short, it’s a job that needs doing.
IF YOU’RE STILL USING DRUPAL 7, GO STRAIGHT TO DRUPAL 9
Drupal 9 is the current and best-equipped version. It’s an evolution of Drupal 8, so the work involved in upgrading from 7 to 9 is no greater than from 7 to 8.
Indeed, Drupal 8 will reach end-of-life a full year before Drupal 7 does – so you’d have to upgrade to 9 before the end of 2021 anyway.
(This might seem a little strange, but Drupal 7 was originally scheduled to finish alongside Drupal 8 in November 2021. But Drupal 8 relies on the Symfony 3 PHP framework, which itself reaches end-of-life in 2021 – so Drupal 7 could be extended in the light of COVID, but Drupal 8 could not. Besides, the path from 8 to 9 is much simpler.)
The good news is that some elements – like migrating your data and porting any contributed modules – should be relatively straightforward.
THE UPGRADE IS A BIG JOB – WITH SIGNIFICANT BENEFITS
There’s no escaping the fact that upgrading from Drupal 7 to Drupal 9 still involves significant work, aligning your front-end code, functionality and theming to fit the new technologies and features.
However, I do strongly believe it’s worth sticking with the platform, for all the reasons you will have chosen it in the first place: it’s a very flexible, extensible system, with wide community support, and its open-source PHP base means you’re not locked in to one provider.
(Admittedly, I’m a longstanding part of the Drupal community – and I have contributed several modules to Drupal.org – so I may not be the most unbiased guide.)
Familiarity is also valuable. Although some aspects have changed, it’s still fundamentally the same platform – so that will minimise the retraining aspects for the team who manage your content.
Drupal 9 also has some significant benefits over 7, including:
Many features provided by contributed modules for Drupal 7 are baked into the Drupal 9 core.
Vastly improved media handling and media library.
Web services in core – allow other consumers to use your content.
Editorial workflows available out of the box.
Content authors can manage page content and layout more easily with the new Layout Builder.
Configuration management built in.
These are just a few of the many improvements made in Drupal 9, most of which simply take the best of the Drupal 7 contributed modules and include them as standard. This means, with fewer contributed modules to manage, on-going support of your Drupal 9 site is easier than ever.
MY VIEW: THE UPGRADE NEEDS TO HAPPEN, SO MAKE THE MOST OF IT
While the need to rebuild is never welcome news, the upgrade to Drupal 9 does give you an opportunity to look at your site afresh, reflect on your business objectives, and make the most of the new features and capabilities to deliver against them.
And this is intended to be Drupal’s first and last update of this magnitude – the plan is for future updates to be far simpler – so it’s likely to be a rare moment. My advice is to seize it.
We also have a pretty clear view of Drupal’s future direction from here, so it’s worth looking at your longer-term business strategy, considering what role your website might play in future, and devising a roadmap to get you there.
If you’d like some help with that, or you have any questions, we’d be very happy to talk to you. Or you can find out a bit more about our Drupal 9 upgrade services here.
At CACI, our Drupal developers are fortunate to work alongside UX specialists, digital strategy experts, and data engineers – so wherever your strategy is going, we’re in a good position to help.
So, the first question on your mind is likely to be what on earth is Rustlr? And indeed, the name can do with a little bit of explaining.
Similar to how a rustler is someone who rounds up and steals sheep or cattle, our browser plugin Rustlr rounds up and visualises data sent from your browser as you surf the internet. It also (among other things!) tries to alert you of other suspected rustlers out there who may be trying to steal your data. Admittedly the link is slightly tenuous, but it makes for a cool sheep icon, a name that rolls of the tongue, and nods towards our west-country location!
The intention behind Rustlr was twofold: For the user, we wanted to provide a way of increasing their awareness of their security footprint while browsing the web. Whereas we, as a group of developers, wanted to try our hand at making an internet plugin. We wanted to focus on usability and make it easily accessible to those who were not necessarily ‘techies’ or internet security experts.
How it Works
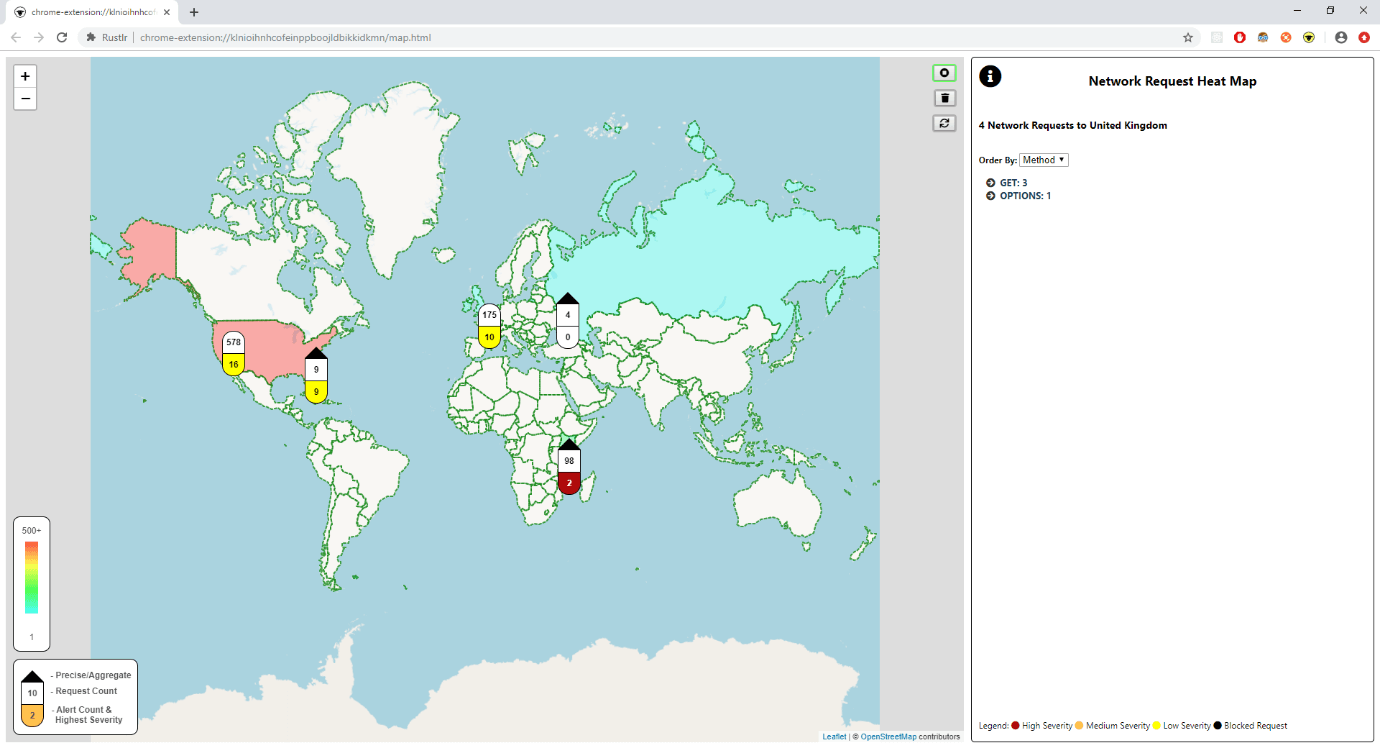
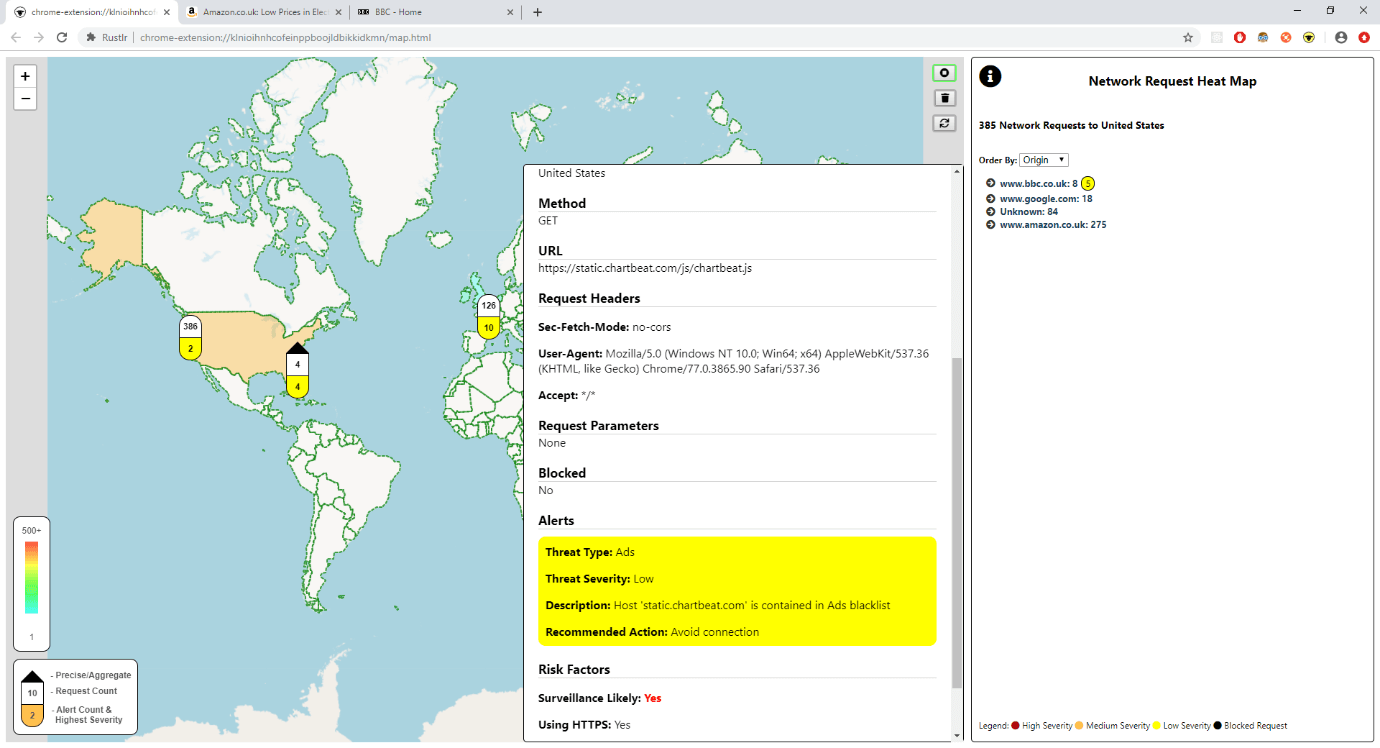
The extension captures HTTP traffic sent from the browser, runs processing on each request to generate a set of alerts, and then displays the results on a map of the world.
The processing step resolves the IP from the hostname, and then uses the Maxmind GeoIP database to find the location the request originated from. It then runs a set of rules on each request, checking for things that look a little suspicious such as the request origin being on a known blacklist, or a password being sent to an unexpected domain. Finally, it sends the resulting set of alerts along with the request to the visualisation layer.
The main visualisation shows a heatmap of the world, built from the count of requests sent to each country, which quickly gives a picture of where data is going. For instance, an unexpected country lighting up when browsing a known website could be an indicator that something odd is going on!
From here the user can drill into the requests sent to each place. They can view request data that an experienced developer may be able to find through Dev Tools. Or they can skip straight to viewing the alerts, which highlight potentially dangerous activity. The icon changes colour as the alerts rack up that, alongside pushed browser notifications, warn the user even when the map is not in view!
Technology Stack
Writing a browser extension, we were tied to using the web development technologies – JavaScript, HTML and CSS. However, we did have room to make a few decisions. We decided to use TypeScript, for all the benefits that it brings, notably reliability and readability.
While the extension API prescribed the structure of the built package, we wanted flexibility in structuring our code. So, we used Webpack to convert our source into the modules that the browser required. We used the browser Web Storage API for persistence to ensure that the whole system could be packaged and loaded in without any external dependencies.
We discussed the idea of using a framework such as Angular or React but decided against it to reduce boilerplate and to avoid introducing another technology into the mix that would have to play nice with the others.
We decided to support both Chrome and Firefox, which can often throw up challenges due to the subtle differences in their APIs. However, we mitigated this by finding a polyfill library that enabled us code against just one common API.
Our main third-party dependency was the open-source mapping library Leaflet which we used for our main visual element. We found it straightforward to use and some of the additional features developed by the open source particularly suited our needs.
Our Development Process
We kicked this off in a team of four and run this as an internal ‘Capability Development’ project. We worked in one-week sprints following the Agile Scrum Framework, albeit a slightly relaxed one, so that we could incrementally build up a more sophisticated solution, while maintaining some focus on the end user.
At the end of each sprint, we demoed to our senior engineering team, who were acting as the customer. One of them played the role of the Product Owner to prioritise our backlog and give us steer in terms of features.
After an initial phase of development of around a month, we had laid down the core structure and implemented many of the initially desired features. This meant that subsequently, it was easy for new developers to pick up the project quickly and slot in their new feature in the established architecture.
UX Journey
In terms of user experience, we began by gathering a high-level idea of what the extension should do from our group of ‘customers’, and how this could be useful. We quickly determined that the plugin should have a visual element, be easy to install and use, and highlight the most interesting information first. As we started developing and receiving feedback, we went on a journey that significantly changed the structure of the app.
A good example of this is that initially we went for a design that popped out the extension in a separate window, and then all further controls were operated from that window. This was seemingly a simple design but it went against the normal convention that browser extensions use – to display a control panel popup below the icon next to the address bar. It was also found to be cumbersome to have to always keep an extra window hanging about while browsing.
Following user feedback during each sprint, we restructured the extension to fit the common pattern, meaning that it would behave as the user expected on their first use, a principal that is at the core of user-centric design!
Final Thoughts
We found that using the Agile development process helped us to stay focussed on the most important features. It enabled us to react spontaneously and change the direction the extension was going in after receiving feedback. It also allowed us to delay some design decisions to when we had a better understanding, instead of trying to guess up-front.
All too often when developing we become over familiar with our product and lose sight of the user’s experience. Sticking to user-centric principles when designing helped us to tackle this to an extent. However, putting our extension in front of someone outside the development team was even more valuable.
We developed using all open-source products, so were very grateful of the strength of the open-source community. It also goes to show that putting together the right mixture of technologies can go a long way.
All in all, we developed an extension that is easy to use, provides useful security information and fits our initial aims!