Bunzl Retail Supplies manages 16,000 product lines (SKU’s) across 70 categories and works with major retailers across the UK including Asda, Waitrose and Boots. Understanding the profitability of each product line, as well as purchasing patterns is critical to maintaining an efficient supply chain.
However, with no real-time data analysis available across the business, Bunzl Retail Supplies could not easily understand enough detail around customer buying habits and the affect this was having on stock levels and delivery costs.
This in turn could produce redundant stock that carried a financial liability. What reporting they did have in place only generated this required level of data every 3 months and as the data was held in three main source systems, integrated analysis was still difficult.
The Solution
Bunzl Retail Supplies decided to implement an analytics solution from CACI to provide a single view of a customer at the SKU level in respect of sales, stock and carriage data on a daily basis, helping them to analyse order volume, order value, carrier costs and gross margin, all against individual product lines and customers.
Managers from across all areas of the business are now able to access the highly intuitive dashboards on a daily basis.
The project was split into 3 key phases:
Sales order analysis by product line, category and customer
Inventory analysis and delivery point profitability
Workforce and operational management performance analysis
“Our business is often about understanding what customers are NOT doing, it’s about exceptions. We needed much more granularity of detail around sales, not just a headline figure. Finding out that we hadn’t sold what we expected to 3 months after the event was causing us some real problems in stock management and profitability.” Jason Greenway, Managing Director
The Results
Phases 1 and 2 are complete and Bunzl Retail Supplies can now make evidence based decisions based on a complete picture of sales patterns, stock levels and product profitability, including for the first time, the costs of carriage. The intuitive design of the solution makes analysing data across the business far easier and with integrated near real-time data updates, changes to customer buying habits and trends can be responded to and actioned upon very quickly.
“We can now analyse sales, stock and delivery data all in one place whenever we need to. Without a shadow of a doubt, the new system has and will continue to save the business money”. Jason Greenway, Managing Director
Phase 3 of the project is already scheduled. This will add in an additional workforce and operational management data source to enable performance analysis to be undertaken for each customer and individual stock picker. The solution will measure real time pick rates and visualise whether the picking is ahead or behind the set standard rate. Improving the actual pick rates will increase the margins within customer contracts.
By analysing data for each individual picker the solution will also offer very good performance measurement and benchmarking.
Commenting further, Lindsay Wilkie, Finance Director added
“Our approach in the past to business intelligence was very limited and not at the level of granularity required to truly help decision making. CACI has helped us to build a much stronger approach and their solution offers the business a powerful decision support system that is flexible enough to adapt as our needs change and develop. Other businesses will undoubtedly benefit from having a solution that offers this level of real time data analysis.”
Every team faced new challenges during COVID-19 disruption, but your technology team might also have faced the monumental task of transitioning everyone in the company to home working. It’s impressive how quickly everyone adapted – but as we explored in the first blog post of this series, that speed has left many companies with some worrying gaps in their security profiles.
Now the dust has settled, and employees are into the rhythm of remote working, it’s time for technology teams to take a step back and assess their security measures. To keep your teams and data sets safe, your technology team should be regularly backing up your data, managing user privileges, and updating your security patches and signatures. If these key maintenance processes are ignored, it could put your entire company at risk.
To help put your mind at rest, we’ve gathered some key security questions you can ask your technology team to ensure they’re keeping your company safe.
QUESTION #1: HOW OFTEN ARE YOU AUDITING USER PERMISSIONS?
While setting teams up for remote working, it’s likely your technology team needed to grant new users access to various applications and storage locations. But now that remote working has become a new normal, it’s important to go back and regularly audit who has access to specific data sets.
And it’s not just about setting the right privileges. It’s also about actively monitoring when certain documents are being accessed. If your company experienced a data breach, it would be difficult to track down the source that caused it without accurate records in place. These logs and ledgers should be managed by your IT administrators, and analysed often to check that important data isn’t being accessed by the wrong users.
Luckily, these steps aren’t difficult. Most cloud storage providers and security solutions offer easy-to-use tools for tracking user privileges and data access reports, and even enable IT administrators to set up alerts for any suspicious activity. But it’s still important to make regular audits and remove permissions when they’re no longer needed – especially at a time when it’s difficult to determine who has access to your employees’ devices.
QUESTION #2: IS OUR DATA BACKED UP – AND CAN WE RECOVER IT WHEN WE NEED TO?
Storing your data on a cloud service isn’t a case of uploading and forgetting about it. Instead, you need to make sure you understand your responsibilities for backing up and protecting your data.
All cloud providers follow the “shared responsibility model”, which dictates which party has responsibility for specific security measures:
As a customer: you’re responsible for everything in the cloud – including your data, the firewalls you use to protect it, and the users you grant access to.
As a cloud provider: they’re responsible for the security of the cloud – including the compute, storage, and networking capabilities.
This distinction means that if an important data set goes missing, it’s not likely you’ll be able to hold your cloud provider accountable. So, whether you use native capabilities built into your cloud platform or create a physical data backup location for critical data sets, it’s important you have a strong replication strategy in place to protect yourself against permanent data loss.
QUESTION #3: ARE OUR SECURITY SIGNATURES AND PATCHES UP TO DATE?
Everyone knows how frustrating updates can be – they take valuable time from the working day, reduce productivity, and are often prompted when it’s inconvenient for the user. And due to these frustrations, many employees don’t keep their devices regularly updated with the latest security patches. But sometimes, a small compromise in productivity can save the stress and cost of a major data breach.
It’s down to your technology team to make sure all patches and security signatures are being kept up to date across your entire team. That means making mandatory, scheduled update bookings – ideally out of working hours – and maintaining a clear visibility of every employee device on your network. And the same process should be made for your cloud platforms too, ensuring you’re effectively protecting your data where it resides.
PROTECT YOUR DATA DURING THE REMOTE WORKING PERIOD
There’s a lot to think about when it comes to data protection, and it can quickly become overwhelming if you haven’t got a clear strategy in place. But don’t worry; we’re here to help.
We’ve created a short, one-page checklist that covers the key points you need to think about when assessing your security profile.
And if you missed the first blog post in our series, take a look to find out how you can strengthen your data management strategy.
The manifestation of trauma in adolescence occurs in a multitude of ways and there isn’t a single response to the expression of trauma. Identifying root causes can be difficult, with trauma hidden and experienced in complex ways, from obvious incidents such as violence and loss, through to long term neglect, structural and institutionalised trauma. The first step towards dealing with trauma, however, is universal – building healthy relationships and recognising what is going on with individuals to facilitate recovery and building resilience.
Identifying, assessing and mitigating the impact of child trauma was the theme of an event CACI hosted recently. At the heart of the panel conversation was how to relate to those young people who come into contact with youth offending services across the UK. How can youth justice workers, social workers and teachers get a joined up picture of each young person to create an understanding of their story to then relate to them?
“We all experience trauma and this is a fundamental part of our response to it,” says CACI Children & Young Person’s Services strategic director, Marc Radley. “Youth offending teams are the only ones able to complete a picture of the end results (in youth) and the stories that lead up to these.”
Is childhood trauma a universal ingredient in persistent youth offending? “We need to assume that all children in the criminal justice system have suffered trauma,” adds Dr. Alex Chard, director at YCTS. “We need to look back at each person’s story and relate to it. Early childhood abuse, especially something as corrosive as neglect, is a vital step in establishing relationships with these young people. Some factors often get missed, such as structural abuse, aspects such as poverty and the impact this has on a child, and social abuse, aspects such as discrimination.”
Joining the dots to paint a clear picture of each child’s experience is difficult. Information is often simplified, siloed and important context lost across the different agency process and practices that interact with a young person, from schools to social workers and youth offending teams.
“Many children have deep issues from the trauma they’ve experienced, and trauma is different for every child,” explains Marius Frank, strategic lead for E-learning development and youth justice at Achievement for All. “There’s not single solution or picture. Trauma exists in a spectrum, manifesting itself differently in each individual. We are seeing some amazing work engaging with young people, though. Moving away from a punishment first outlook to one of understanding is a step in the right direction. We need to continue moving to trauma informed practice from trauma awareness.”
Putting the trauma front and centre of the response to youth offending will enable youth offending teams to better understand the individual they are dealing with. “Research on family and that sense of belonging is crucial,” adds Sonia Blandford, CEO of Achievement for All. “How can we create that feeling of connection in the young person?”
It is often the case that trauma affected young people have experienced a continual carousel of rejection, which results in a deep mistrust of adults and, therefore, present very challenging behaviour seen in youth offending teams as they go about their work. “This is the compound impact of multiple trauma points,” says Shaun Brown, programme director at The Difference. “There are a broad range of institutional experiences in response to this.”
Finding a route to engaging with young people who have experienced complex trauma is incredibly challenging, but it is possible. By working to get a holistic view of each young person it is possible to piece together story and begin to understand how they got to where they are. Understanding leads to positive relationships with workers to reduce offending. Further, when these stories are made visible via the right structured qualitative and quantitative recording and reporting, whole services gain insight and learning. This is where youth offending services create value and provide vital information about where and how to target resources and monitor future impact.
There are signs that local systems are moving in the right direction and youth offending service partnerships are at the forefront of this. They are building local knowledge, experience and understanding of the impact that trauma is having in young people’s lives. Bridging that experience into other agencies and organisations involved can restore healthy relationships with these young people and protect future generations, but only if this effort is continually monitored.
You can watch a recording of our panel session below
One of the cornerstones of helping young people who have experienced trauma is establishing supportive environments and relationships in which they can begin to address their adverse experiences. For the majority of young people who have experienced trauma, there is a lack of trust in adults and services around them, so establishing these environments and these relationships is not only extremely challenging, but extremely important.
The topic of establishing these support tools was discussed at our recent panel event, identifying, assessing and mitigating the impact of child trauma.
One of the issues identified in establishing positive relationships with these young people was the number of case workers that can become involved in their story. “This goes to the heart of the relationship and the view of the young person themselves and their experiences of the different agencies involved in their life,” says Sonia Blandford, CEO at Achievement for All. “I’ve seen cases where there are as many as 12 professionals involved with a young person, each one with a different opinion and a different attitude.
“If we can change the behaviour of the adults we will improve outcomes for the young person. Everyone needs to be singing from the same song sheet. A multitude of approaches is to the detriment of the young person and our overall response to their trauma. Families, too, will kick back against the system as it’s not helping them – we need to reduce the number of people involved with each young person.”
So where, ultimately, should the responsibility lie? “We need corporate visibility of young people in the youth justice pathway,” says Marius Frank, strategic lead for E-learning development and youth justice at Achievement for All. “There have been huge changes in outcomes for looked after children when the responsibility for them has been moved to local authorities. If responsibility lies in one place, we reduce the risk of fragmentation of information on these children.”
This is a point that Alex Chard, director at YCTS, agrees with. “It is intentional that school records are kept separately,” he says. “Records should be joined up, but there are obstacles to achieving this, not least the fact that there are a number of young people known across different systems and this isn’t being recognised, which is creating more risk.
“We need to look at families and inter-generational trauma. We gain a different level of empathy when we care to understand a young person’s history.”
Understanding, therefore, is central to enabling fair access for these young people and establishing positive environments and relationships with them. “Young people who are ‘difficult to like’ consistently experience rejection,” adds Shaun Brown, programme director at The Difference. “We are conditioned as human beings to reject experiences that cause us discomfort, which goes some way to explaining why these young people are the way they are.
“Building and sustaining relationships with these young people has to be front and centre of our response and we need to monitor what this achieves within our institutions. This needs to be achieved through the layers of the system.”
Establishing relationships with trauma affected young people can be extremely challenging but understanding where our response to it has gone awry can help to put in place in effective building blocks for improving outcomes going forward. A unified system response, with a consistent approach from the professionals involved, will go a long way to ensuring fair access to supportive environments and relationships for these young people.
Communication Service Providers (CSPs) are well known for having the advantage when it comes to the volume of network and customer data they hold. They aren’t new to handling huge volumes of data and are generally considered to be better at exploiting it than some other industries.
However, when it comes to Big Data projects, CSPs face challenges too.
Here we explore some of the hurdles CSPs may encounter on a Big Data project.
Buy in from the business
Before looking at the technical and project issues, we must start at the beginning, the planning stages which include getting the project signed off and ticking all of the right boxes.
Challenge:
The Business Case
The outcomes and benefits to the business are key when taking on any project, determining the need and key deliverables. Before starting a Big Data project it can be difficult to showcase the potential value without having a few insights and pieces of evidence to support that the insights from the data will add value.
Solution:
Working on a small but strategic basis to start can help to address this challenge and may help when it comes to formulating a stronger business case to showcase to the top management of a CSP in order to help with buy in.
Challenge:
The Legal and Compliance requirements
Considering the amount of customer data a CSP holds, there is often a drive to monetise this as much as possible. This creates an issue when it comes to regulation and customer privacy
Solution:
A solid foundation of Data Governance should be implemented. This helps protect customer data wherever it is, as well as mitigating the risk of it being used inappropriately, and ensures the goals of the Big Data project can still be met.
Getting technical
There are 2 fundamental technical challenges CSPs will need to address when undertaking a Big Data project, we address them both below.
Challenge:
Data Sources and Volumes
As technology advances including use of connected devices, the Internet of Things (IoT) and 5G, the sources from location services, apps, social media and streaming all create previously unthinkable volumes of data from more sources than ever before. The question is how to manage it all.
Solution:
It is crucial for CSPs to be able to consolidate all of these data sources and volumes into a single version of the truth in a format that can facilitate analytics and actionable insights.
Challenge:
Internal CSP Data Silos
Within the CSP data will be stored in different systems, across different departments, processed and stored in different ways, sometimes over such a long period of time it is almost impossible to have a complete view of what data is actually held across the CSP. These data silos create the challenge of being able to share and consolidate all of the data in order to make a success of your Big Data project.
Solution:
The first step towards consolidating your data management systems is to run and audit across the business to identify what processes and systems are contributing to the silos and what data is held where. This information will support effective decision making on how to move forwards.
People, resources and development
One of the common hurdles businesses run into, CSP or not, is the struggle of time and resources. Whether you don’t have the skills to complete a project in house, or the time available vs the complexity of the project itself.
Challenge:
Skills Shortage
The resource and skills required on a Big Data project are often underestimated. The ability to understand, evaluate and implement the technology is key, alongside the expertise to undertake advanced analytics and the business acumen to turn insight into action. Often CSPs may have one or a few of these skills in house, but could be missing a critical piece of the puzzle.
Solution:
Access to outsourced consultants through your supplier or a partner can often mean fulfilling the missing aspect temporarily or permanently, or working with a supplier to obtain support days for short term projects or training that will upskill your in-house team.
Challenge:
Development required to integrate solutions
More often than not, achieving all of your Big Data goals requires a number of connected technologies to create a holistic solution. This can lead to an increase in development work, as well as the requirement for skills across multiple systems.
Solution:
Vendor partners of systems you may be using, or consultancies that work across multiple platforms can often connect the dots between the various technologies and tools required. They can pull together a solution specifically designed against the outcomes and deliverables of the Big Data project.
As technology advances and data volumes and sources grow, so does the demand to do great things with Big Data. With this increase in demand comes a need to overcome these challenges, generate data insights and turn them into actions.
Data insight and intelligence will help CSPs keep ahead of their competition and keep their customers happy, as long as they act quickly.
The year of 2020 has brought with it many challenges, not least of which is the need to stay connected. The recent reliance on digital services to keep families, friends and businesses in touch is an added pressure and opportunity for the Telco industry who are already taking on the challenges presented by the Internet of Things (IoT) and the roll out of 5G.
Along with these new challenges and opportunities comes a time for these companies to ensure one thing moves up in the list of priorities: Master Data Management (MDM).
A MDM solution not only brings systems and information together, but creates a single version of the truth. An accurate and trusted, complete view across customers, operations, supply chain, governance and more.
Here we look at some of the key uses and benefits telecoms can get from MDM.
The customer is king
It may seem obvious that we would list the importance of the customer and their data to any telco company, but what is often less obvious is just how complex customer data can get; and that without a full view of the customer, new opportunities can be easily missed and the chances of them jumping ship are substantially increased.
When we start to delve into the sources and various data held by just one customer, it can span across subscriptions, family members, tariffs, bolt-ons, bundles and more. If this information isn’t properly stored and managed, Communications Service Providers (CSPs) can quite easily make big missteps that make the customer immediately think “you don’t know me” – which in the world of tailored online marketing, creates negative brand associates overnight.
While customers might not say it out loud, the expectation is that their CSP has a complete 360-degree view of them, across from their accounts, their relationships, their history with the CSP, interactions (whether that’s by phone, email, in-store or social media) and more. Plus, to really stay on top of future opportunities the CSP also needs to be looking at the customer’s network usage and behaviours. By taking this 360-degree approach the CSP is far more likely to create the right offer at the right time, reduce customer churn and even increase products bought within their existing customer base.
Considering these facts and that it is widely accepted that customer retention and relationship building provides more potential revenue than the acquisition of a new customer, CSPs must prioritise implementation of solutions such as MDM that allow them to better understand and react to their customers and access this potential revenue.
Protecting and producing products
Managing the chain of suppliers and products is not as straightforward as it may sound, especially where CSPs are concerned. Between the contract products of various tariffs, the digital subscriptions such as video and channel content and the hardware of different suppliers, “product” suddenly sounds much bigger.
Across these products, information is stored, managed and presented in different (and sometimes multiple) ways, creating a complicated task, especially if it’s being done manually. This will often be done by various people across the business, working in different departments.
What MDM solves for products is a way to centralise all of this information, turning large volumes of data into a manageable data set that helps a CSP to better manage all of their processes.
Opening up new revenue streams
As some more traditional revenue streams dry out, the pressure is on CSPs to look to other areas of their ecosystem for opportunities and new revenue streams.
One of these opportunities may come from the growth of connected devices and the IoT. As more and more consumers connect their home appliances, CSPs can gain increased data insights from larger volumes of data than ever before.
In addition to this, as we meet the new reality of 5G rollouts, previously unthinkable volumes of data will soon become the norm. This could not only help telecoms improve efficiency, but also open up a new stream of revenue by taking a network slicing approach to enhance network monetisation.
Once telecom’s begin to go down this route the importance of MDM becomes apparent very quickly as the data volumes need to be effectively managed.
The future of MDM for CSPS
To keep the competitive edge and meet customer demands, implementation of a MDM solution is becoming increasingly crucial.
CSPs have historically invested in key systems to support these goals such as CRM, ERP and Network management systems. With those in place a solid MDM solution provides the boost the CSP environment needs to drive improvements, efficiencies and ultimately business growth.
Over the past months, we’ve all had to adapt to home working and rapidly equip teams with the tools they need to continue operating as normal. This quick shift has forced organisations to adopt new systems and services, from cloud storage platforms to file sharing tools, to keep teams connected and offer easy access to the data they need.
But in many cases, the pace of change has been prioritised over data protection. Some organisations are now left without a clear view of their security profile – creating rich opportunities for fraudsters. That’s why it’s critical you have a clear view of where your data is, how it’s being used, and who’s using it at all times of the day.
Don’t panic though; filling these data security gaps doesn’t need to be difficult. In this blog post, I’ll ask three important questions about your data. Answering them will help identify some easy ways to strengthen your security profile and keep your data safe.
QUESTION #1 – DO YOU KNOW WHERE YOUR DATA IS?
Even before the shift to home working in 2020, it’s likely you were either already using cloud services, or in the process of migrating some of your key resources to one. It’s a great way to lower your costs, improve collaboration across your teams, and give employees access from remote locations. But while cloud platforms provide plenty of benefits, there are a few security risks to look out for.
With many cloud platforms, it’s not always clear where your data is physically being stored, or how it’s being used. Even if you’re accessing your cloud service from the UK, many software-as-a-service (SaaS) and cloud storage providers rely on international data transfers and remote data centres to store and manage your data. And if you’re an organisation that handles sensitive data that’s bound by tight regulations, this process can create some major challenges.
When considering a SaaS or cloud provider, look closely at their data sovereignty policies, and ensure you have a clear understanding of where your data is being managed. The big three cloud storage providers – Google, Microsoft, and Amazon – all have data centres across the globe to solve this issue, and often let you choose exactly where you want your data to be kept.
Alternatively, if your organisation has specific sensitive data sets that can’t be stored on a cloud platform, you could use a hybrid cloud model to gain greater control over how your data is stored managed.
QUESTION #2 – WHAT DEVICES ARE ACCESSING YOUR DATA?
When you sent your employees to work from home, you may not have had the budget to equip everyone with new laptops and mobile devices. And that’s okay – many organisations encourage people to use their own devices for working; it saves additional costs and improves convenience for employees. But if you’re taking this approach, it’s important you have strong, standardised security measures in place.
Using personal devices can create new data security risks that might not be immediately clear. For example, most employees will be the system administrator of their own device – whether it’s their home computer or their mobile phone – which means your technology team has limited control over their security settings. If just one person’s device is compromised, it could offer direct access to data and company infrastructure.
And it’s not just digital security you need to consider – it’s the physical security of those devices too. With employees spread across different locations, it can be difficult to know who has access to their devices. In most cases it’s likely just family members, but in a worst-case scenario, it could be a thief looking to gain access to your data.
Our advice:
Overcoming risks related to personal devices is easier when you have strong endpoint security measures in place. These can often be as simple as making regular, automatic endpoint health checks using a dedicated security solution, or sometimes even native cloud platform features.
It’s also a good idea to take the time to educate your employees around common threats like phishing attacks, to ensure they can identify them when they happen, and avoid compromising the rest of your company.
QUESTION #3 – HOW ARE YOUR PEOPLE ACCESSING
YOUR DATA?
In most modern workplaces – from schools to investment banks – employees need to transfer files to each other, access shared data, and even collaborate on the same documents. When all your teams are in the office, it’s easy to connect everyone through your company’s network – but at home, it’s a new challenge.
Many businesses have turned to virtual private networks (VPNs) for a quick, user-friendly way to connect employees from remote locations as if they’re working in the office. It’s a convenient solution, but it also comes with the compromises of reduced defence against malware, limited control over employee devices, and a lack of protective resources.
In other cases, employees may have adopted their own methods of file sharing. Popular tools like WhatsApp messaging and email are all handy for sharing low-risk documents in our personal lives, but they can’t offer the robust security measures needed for handling sensitive data.
Our advice:
To prevent employees taking file sharing into their own hands, you need to ensure you’ve got a secure, reliable, and easy way for employees to access and share data.
That might be a robust cloud platform that enables real-time document collaboration and secure data storage, or through your existing infrastructure using dedicated security measures to protect transfers.
STRENGTHEN YOUR REMOTE WORKING SECURITY PROFILE
Data management is just one half of what it takes to create a strong remote working security profile.
The concept of child trauma is a fluid one. There are the obvious examples that we can think of, those that social services and professionals deal with on a day-to-basis. Then there are the more intangible experiences of trauma, such as long-term neglect, structural and institutional trauma. The responses to behaviour by the professionals involved, be they teachers, youth offending teams or care workers, play a crucial role in the outcomes of these children. How can we work with conflict and challenge to join often disparate parts of our responses to create a roadmap to improved outcomes for all children?
CACI recently hosted an event exploring this topic. We were joined by a panel of domain experts: Alex Chard, director at YCTS; Shaun Brown, programme director at The Difference; Sonia Blandford, CEO at Achievement for All and; Marius Frank, strategic lead for E-learning development and youth justice at Achievement for All. The event was hosted by our Children & Young Person’s strategic director, Marc Radley.
How can we relate to children who have suffered lifetime trauma who find it hard to recover and build resilience?
“Understanding the history of these children is the responsibility of everyone concerned with their story,” says Alex. “We have to understand every child in youth offending services. At the moment we tend to ‘snapshot’ risk and tend to the most recent events. We need to look back further. We also need to assume that all children in the criminal justice system have suffered trauma. Gaining an understanding of early childhood abuse, especially something as corrosive as neglect, is a vital step in establishing relationships with these young people and building up their resilience.”
In what way do our system responses help or hinder recovery?
This was identified as an area for improvement by our panel. “There are so many layers in the systems that we operate and we tend to focus on what we know and understand,” explains Sonia. “These need to be an overarching view of every child; instead we have simplified information in silos. System responses, therefore, are a hindrance and can even exacerbate the difficulties for the child. We need to find ways to share our knowledge across the board and in order to learn and improve, we need to eliminate unhelpful routes and make things simple. At the moment there are too many layers.”
“Chronology and understanding of vulnerable children is hindered by misplaced fear of protecting privacy,” says Shaun. “Where access to past information is restricted, we can only see current information and there is no context. Understanding gets lost and many young people are left continually restarting their journeys.”
There is also the educational aspect in all of this, away from youth justice teams. “Assessment has failure built into it and this is a form of institutional trauma,” explains Sonia. “A lot of these children are always failing exams and tests and being told they’re bottom of the pile.”
“For some 14- and 15-year olds the first time they are diagnosed with severe educational disabilities is at screening by a youth offending team,” says Marius. “Why? Because of exclusions. This is driven by high stakes assessments and a results driven system.”
How do we enable fair access to supportive environments and relationships?
“We need to look at families and intergenerational trauma,” says Alex. “We gain a different level of empathy when we come to understand a child’s history. For this, we need joined up records, but there are obstacles to achieving this, not least children being known to various professionals across different systems. Where this isn’t recognised it creates more risk.”
Shaun adds; “children who are ‘difficult to like’ have consistently experienced rejection. Building and sustaining relationships with them has to be front and centre of the response. We then need to monitor how that works within our institutions and responses through the layers of the system.”
“We see too many cases where there are too many professionals involved with each young person, sometimes as many as 12,” explains Sonia. “That’s 12 different people coming in with different opinions and attitudes. If we can change the behaviour of the adults, we can improve the outcomes for the children. Everyone needs to be singing from the same song sheet. Families will rail against an inconsistent system that doesn’t help them – we need to reduce the number of people involved with a young person.” Although, this means we must also value and support those workers who step in.
How do we work with these understandings about risk and vulnerability?
“We need to get children out of the criminal justice system who shouldn’t be there,” suggests Alex. “Only dangerous children should be in there. We could then reduce the number of children going through youth offending teams and this will result in a better system for the most vulnerable children in society.”
“There are profound lessons to be learned,” says Marius. “We need to re-examine why children are in the youth justice system. We need to improve protection and early identification. We need to work around the young people as early as possible.”
“For all that, there’s an awful lot of good work going on and there’s clear evidence that a child first approach is working.”
Want to know more? Watch a recording of this event below
For most organisations collecting, processing and managing huge volumes of data, there is a looming question: “what next?”
Now we have the data, how do we put it to good use?
The first requirement when you’re looking to make the most out of your data, is to ensure your users are educated and empowered to understand and interpret that data.
Here’s where data literacy comes in…
What is data literacy?
Data literacy is defined as the ability to read, work with, analyse and communicate data in context. When both business leaders and employees are data literate, they are empowered to ask the right questions, build knowledge, communicate meaning to others and make better decisions.
It has become critical for everyone in an organisation, not just data scientists and analysts, to have access to and basic knowledge of reading and interpreting data. Staff are then able to combine their own expertise with these data literacy skills to gather insights that produce more accurate and tangible business outcomes.
Why is data literacy important?
It is predicted that by 2025 there will be a ten-fold increase in worldwide data. For data-driven organisations, this will generate a need for more data literate employees that are able to inject intelligent insights from data, back into the business. These insights can be used support goals such as service delivery improvements or keeping the edge over the competition.
Organisations that lack in sufficient data literacy skills should be looking include developing data literacy competencies as part of their data strategy, and those who don’t will risk creating a roadblock to success and inhibit future business growth.
Jordan Morrow, Global Head of Data Literacy at Qlik, made the argument in his 2019 TEDx Talk that everyone should be data literate. Referring to the now well-known phrase that “data is the new oil”, he made the case that “data is a valuable asset, and just like oil, it has to go through people and refinement to get value”.
If data cannot create success without people using it effectively, then it stands to reason that technology and training must be treated with equal importance.
Technology vs. Competency
Organisations regularly establish a need for a technology-based solution in order to facilitate or achieve a goal. This can often require a significant investment both for the initial implementation and the ongoing service (licensing etc.). While any costs should be justified by the business requirements and value the technology can bring to the business, data analytics solutions are only as useful as the insight that can be derived from them. These insights prove extremely hard to extract if the technology is not underpinned by a data literate organisation. However, when an analytics solution and education of the workforce is delivered hand in hand, the organisation is in a much stronger position to unlock the best opportunities from data.
There is of course the alternative, whereby an organisation may choose to externally recruit new highly skilled and data literate employees. The challenge presented here is that those recruits may hard to find and require an additional investment from the business. By instead choosing to train existing staff and developing in-house teams, the organisation is more likely to see a better return on investment.
Do I speak data?
As businesses begin to democratise their data to allow the end user increased access to information, it becomes more important that the information shared allows for effective decision making and is easily understood by all who absorb it.
While it may be widely accepted that there is a business value to be gained from data literacy, an assessment on how data literate the organisation is in its current state will help inform the best path to improvement.
Barriers can be caused by lack of communication, skills or knowledge, meaning that data is not being used to it’s maximum potential. Through this assessment, those barriers can be identified and eliminated.
Such gaps might include:
A struggle to identify trends and anomalies
Lack of understanding of the difference between reporting and analysis
Unsure on what to produce to meet requirements
Overwhelmed by data and unsure which data is relevant
Often, organisations might be part of the way through a data strategy through adoption of technology or recruitment of analysts and wonder why they have hit a wall where little seems to have actually changed. Data has been processed, reports have been produced and so on the surface it looks as though the work has been done to facilitate new insights. Stakeholders may be drowning in reports, and yet remain disappointed on the lack of insights or improvements obtained from the data.
The answer may lie in how data literate the organisation is. A key component in determining what is valuable and meaningful comes from data literacy skills. The ability to ask and answer the right questions from your data, not just visualise the results, but visualise them in a way that can be shared and understood.
By answering the points above, you should start to get a clearer view on where your organisation is in its data journey.
What next?
Once an assessment of the organisation has been completed and gaps identified, we return to our original question: what next?
Sourcing an external provider to deliver data literacy training courses can be the first step towards a more data literate workforce.
Whether your organisation is looking to make better use of an existing data analytics solution through better informed insights, or just at the beginning of your data journey, CACI can help.
Our tailored training courses are delivered as interactive workshops by our Business Insight skilled instructors. Supporting material will provide continued informative guidance for staff to actively implement new skills, and data literacy “Personal Training” sessions help go the extra mile towards becoming a data-driven organisation.
Find out more about how CACI can help your organisation become data literate.
Rust has quickly become one of my favourite programming languages with its brilliant tooling and rich type system. In recent times, its community has been working towards making it a language for the web, both on the server and in the browser.
As a systems language that may be a bit of a surprise. But how can it run in a browser? Enter WebAssembly.
WebAssembly (wasm) is a nascent technology initially aimed at providing an assembly language and runtime environment for web browsers. This has since been broadened to a portable assembly and runtime, not just the web, with several efforts in creating portable runtimes (wasmtime, Lucet, wasm-micro-runtime, waSCC, et al) with host system interfaces (WASI). This evaluation is however limited to running rust compiled to wasm in the browser.
Wasm enables code written in languages that usually target native platforms (such as C, C++, Go & Rust) to be compiled to portable bytecode like Java or C#. In web browsers, this bytecode is executed in a sandbox environment entirely within the JavaScript VM. Wasm modules can be loaded and invoked from JavaScript and JavaScript code can be invoked from wasm modules, though there are currently some limitations with tooling that make some of this difficult (see below).
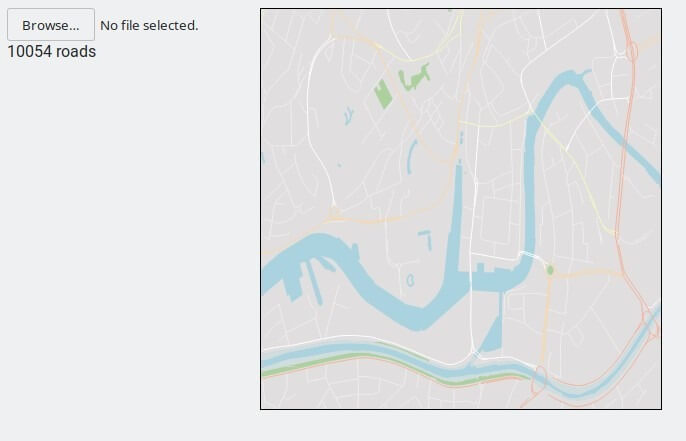
As a proof of concept, a few months ago I created a very basic map drawing application written mostly in Rust. It takes OpenStreetMap data as input and plots and draws this on a canvas element, producing a line-drawn map of the area including roads and some natural features.
Here’s how part of central Bristol looks:
The map can be zoomed in or out by scrolling within the area and it can be clicked and dragged to move it around. This basic functionality is responsive on my machine at least. The coordinates to plot are calculated in advance and kept in memory as I found this to have the best performance overall once more things were being drawn.
Using the canvas to draw, scale and translate resulted in jittery dragging and poor-quality scaling. I didn’t have any success with drawing to a canvas offscreen and then loading this to the onscreen canvas. OffscreenCanvas is only partially supported in Firefox so I didn’t get very far with that, but I also couldn’t get CanvasRenderingContext2D to work offscreen either.
This has all been a learning experience and I’m sure I’ve made some (probably obvious) mistakes. Much of what has been done resulted from workarounds of individual issues that I could see being done differently now. Anyway, here is an account of my experience with it based on how things were earlier this year – there may have been improvements made to the language over the last few months.
JAVASCRIPT + RUST
The Rust WebAssembly working group has provided some tools for working with this. Rust code targeting wasm can call JS code easily through bindings generated by the wasm-bindgen tool and library. This is typically used to annotate Rust code to export bindings to JS (generates equivalent-ish code and glue), or annotate ffi declarations to import JS code. The wasm-pack tool is used for doing all the steps required for compiling Rust to wasm, generating JS glue code, and packaging it all up, invoking wasm-bindgen as necessary.
Many Rust crates (libraries from crates.io) can be compiled to wasm and so can simply be added to your project’s Cargo.toml as a dependency, although there are some limitations to this (see below).
EXPORT TO JS
Rust structs are exported as classes to JS when marked with #[wasm_bindgen]. Since Rust doesn’t have constructors, an associated function can be marked with #[wasm_bindgen(constructor)] to be exposed as a constructor so that a class can be instantiated with new Example(data) in JS (see image below). There are all sorts of variations on this that can be seen in the wasm-bindgen docs.
IMPORT FROM JS
JavaScript functions can be called from rust through the use of bindings.
Snippets
Import from a snippet packaged beside Rust code (see image below). Note that the wasm-bindgen tool is not currently capable of allowing module imports within the snippets imported this way.
JAVASCRIPT AND WEB APIS
Built-in JS types and APIs are exposed to Rust with the js-sys crate. Web APIs are exposed in the web-sys crate, using js-sys where necessary. Both of these crates are fairly low-level bindings only and aren’t always easy to use from Rust or at least aren’t idiomatic.
Notable features:
web-sys contains bindings for everything I’ve tried
JS-style inheritance maps quite well to Rust (which has no inheritance)
Deref trait is used such that a type may be “dereferenced” automatically to its parent type where necessary, similarly to how smart pointers get dereferenced
Typical issues:
data type conversion to JsValue
often via JSON strings for non-primitives
every data type in web-sys is behind feature flags
great for generated code size
less great when you have to keep adding flags to the build for every little thing
makes auto-complete not work(!!)
wrapping closures is cumbersome
overloaded JS functions have to be separate in Rust
eg. CanvasRenderingContext2D.createImageData() in JS is create_image_data_with_imagedata and create_image_data_with_sw_and_sh in Rust for each overload
not an issue exactly, but there isn’t much integration with rust’s mutability and ownership model
everything is &self even though state may clearly be modified
stdweb
Interestingly there is also the stdweb crate. Whereas web-sys aims to provide raw bindings to the Web APIs, std-web aims to bring more idiomatic Rust APIs and doesn’t utilise web-sys at all. I opted to stick with plain web-sys for a couple of reasons: stdweb doesn’t have IndexedDB support so I had to use web-sys anyway, and web-sys is the official Rust wasm library for this, and there isn’t interoperability between these. This situation may change in the future and I did read some comments from the author that hint at basing stdweb on top of web-sys.
LIMITATIONS
Crates
Many crates are written under the assumption that they will be used in a proper operating system environment, not a web browser sandbox. IO (emscripten manages with emulation, why not Rust?), processes, multi-threading (there is some experimental support using Web Workers) are among the things that will fail at runtime with wasm compiled rust code. This was pretty frustrating. I would add a dependency and write code to integrate it, only to have it fail at runtime because it parallelised some computation, or read from or wrote to a file for example.
I believe a better approach given the current status of tooling would be to use a webpack with a wasm-pack plugin and some other plugin to generate a Rust crate from an npm package, rather than use wasm-pack directly. This hasn’t yet been explored but I’ve seen at least one example somewhere that does something like this.
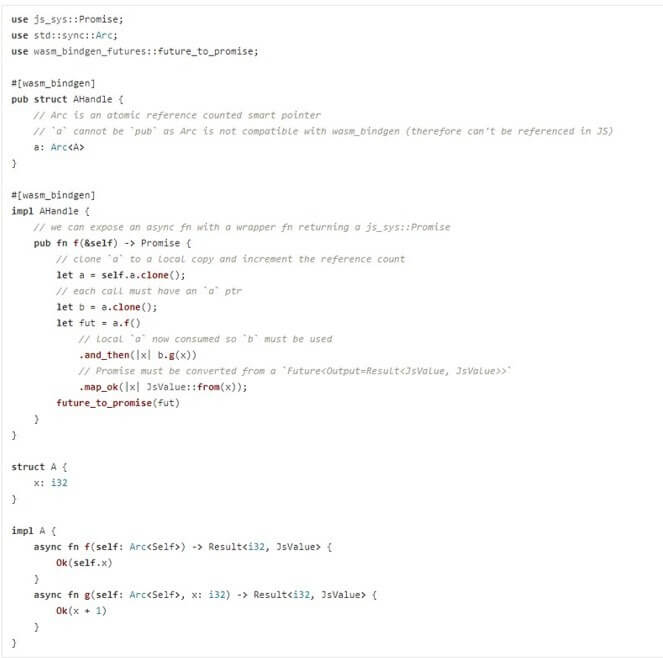
Asynchronous functions in Rust have recently been stabilised using futures as the building blocks. This works well and even integrates with JS using Promises, thus opening the door to interfacing with asynchronous Web APIs in a natural way. The main problem I faced was that to use async methods, I had to have this method consume self not take by reference due to Rust’s borrow checker (even though most of the time these functions were fine when not marked #[wasm_bindgen]). This is OK for one-off function calls for one-off objects, but once this function is called, the object cannot be used again. Rust side gives compile time error. JS side the pointer is nulled and a runtime error saying “a null pointer was passed to Rust” will be given.
The best method I’ve found so far for dealing with this is shown in the image below – where A is the struct with the async function(s) to expose. This is far from ideal, but it’s mostly the result of exposing these async functions to JS. I’m certain there are better solutions to this.
IndexedDB
IndexedDB is a browser-based NoSQL database with a JavaScript API. This has been used to store OpenStreetMap data in a lightly transformed state, which the application then reads on load to feed the map plotting. This works well and IndexedDB is promising for offline storage, though I’ve not explored some of its actual database features, namely indexes and queries. Since this is browser technology it is available to any language that can access browser APIs.
IndexedDB has a completely asynchronous API but pre-dates Promises and is quite awkward in JavaScript, let alone Rust. A wrapper library indexeddb-rs has been used for interacting with IndexedDB, but this was incomplete (and doesn’t compile in its current state at 371853197233df50069d67f332b3aaa3b555b78c). I’ve filled in some gaps to get it to compile, upgraded to the standardised futures version, and implemented basic transaction support so that I could manipulate database structure and insert and retrieve data. My fork is a submodule in this repo in indexeddb-rs and available on gitlab. Ideally this would be contributed upstream.
I had initially used Dexie for interacting with IndexedDB but this proved too cumbersome no matter which way I tried it (binding Dexie directly in rust, creating small wrappers in JS and binding these, doing all DB work JS side and sending this over to Rust).
Pure Rust Application
I’ve found that many of the issues mentioned here stem from trying to combine JavaScript and Rust application code rather than writing all in one or the other. The official tutorial goes this route of having JavaScript driving the application so I attempted to follow. When I began I wasn’t quite sure how to make the jump to a pure Rust application given the constraints of the wasm runtime. You can define an entry point function (or simply call this entry point from JS) with some kind of application loop but dealing with state becomes quite difficult within this, particularly when you bring async functions into it (required for IndexedDB interaction). Although now async functions can be exposed as start functions so the situation has improved since this began.
Some Rust application frameworks exist that seem promising for this purpose, some taking very different approaches from each other: Seed (web front-end framework), OrbTK (multi-platform GUI toolkit with wasm support), Yew, Percy, and more. Yew seems the most mature and has some traction in the community, but it’s based on stdweb and also doesn’t integrate well with futures or async functions, instead using an actor model for concurrency. Sadly I don’t think any of these are ready for production.
Seed
Seed is a Rust front-end framework targeting WebAssembly, strongly influenced by Elm and React. It’s based on the official libraries/tools web-sys and wasm-bindgen so integration with other things is/will become easier. It also has an easy way to invoke async functions so that’s nice. Unfortunately seed is quite immature overall and gives no stability guarantees right now. Though it is quite approachable if comfortable with the Elm model.
OrbTK
OrbTK is a GUI widget toolkit aiming to be cross-platform for desktop, mobile and web applications. Whilst it’s early days it is usable already and the examples are quite understandable. What’s interesting about OrbTK is not just its platform-independence, but also that it’s backed by some quite interesting technology like an ECS (entity component system) to manage state and a FRP(functional reactive programming)-influenced API. It was very easy to compile some of the examples to target wasm and the widget-based examples run almost as well as they do as native desktop applications. The canvas example has very poor performance in browser however (looking at the code it appears to be using both a software renderer “euc” and its own bitmap renderer, not web canvas). Still clearly a long way to go for OrbTK but it’s a promising GUI framework, something which Rust is lacking.
Gloo
Another that’s worth mentioning is Gloo, also from the Rust Wasm group. Gloo is a modular toolkit to help with building web applications rather than a full application framework. Currently it has modules for events and timers, basic building blocks but a good start. Seed already uses some of Gloo and has stated it will continue to do so as it develops.
CONCLUSION
As it stands, many of the pieces are in place for WebAssembly to take off as a platform for secure and performant code execution on the web. It appears to be getting more and more popular outside of the web too, especially in cloud and serverless environments. It reminds me a bit of the JVM in some ways, just with a much lower level execution model which allows languages like C, C++, Rust and Go to target it.
For web applications, I think that Rust + Wasm is an option, with some caveats. Rust has a steep learning curve itself, but since most of this ecosystem is new or abstracting old with something new, it all has a learning curve. The Elm-like model adopted by front-end frameworks like Yew and Seed does seem to work well with the Rust way of doing things. But I couldn’t say whether it has any advantage over Elm or React with JavaScript or TypeScript, other than not having to write much or any Javascript and a different set of tooling. Rust’s strictness with ownership got in my way quite a bit, though as mentioned above I think this can largely be attributed to trying to use both JavaScript and Rust together with async functions. For offline apps, IndexedDB makes persistent data storage in-browser a breeze whether from JavaScript or WebAssembly. So really, Rust is just another language that can run in the browser. Rust itself has some great language features, but I haven’t gone into any of that here.
So in answer to the title question – not yet. But watch the space.