How to determine whether your network is ready for AI
Share this article
You’re busy, and so is your network. Or if it’s not, it’s about to be. AI workloads are coming for your network, and to remain competitive in a world where AI-enabled applications and workflows become the norm, it must be embraced.
Networks are collectively facing their next pivotal moment of transformation and must therefore equip themselves with the necessary network automation and NetDevOps practices to sufficiently operate and enable AI.
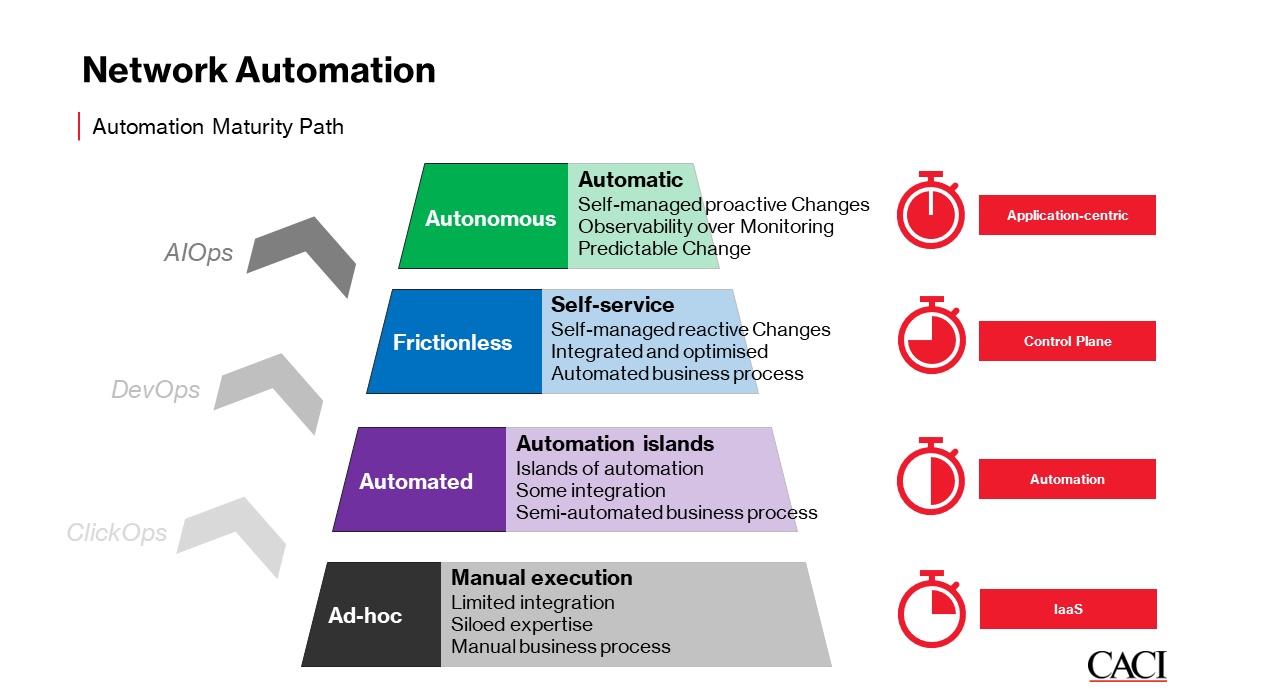
What steps can be taken to prepare a network for AI?
As organisations strive to control the power of AI, it’s crucial to ensure that their network infrastructure is prepared to support these advanced technologies.
In our experience, AI has two key implications to network environments:
Changing the operation of the network
- AIOps fundamentally changes some monitoring approaches such as the Network Management System (NMS) trap and poll of yesteryear towards observability approaches, leveraging streaming network telemetry
- Finding signal in the noise of network alarms shifts from “hard” to “impossible” without the assistance of AI that AIOps brings.
Changing the deployment of the network
- AI workloads are fundamentally different to traditional IT workloads, requiring network topologies that can sustain low flow entropy, high flow burstiness, elephant flows and near-100% bandwidth utilisation
- Stock Ethernet isn’t the only player on AI networks, often utilising RDMA-approaches and protocols such as RoCE and InfiniBand, which require differing abilities to design, deploy and operate.
By taking the following proactive steps, businesses can not only enhance their operational efficiency, but also position themselves as leaders in the AI-driven future.
Evaluate the current infrastructure for AI compatibility
To ensure your network is ready for the AI era, start by thoroughly understanding and evaluating your current infrastructure for AI compatibility. This includes assessing the following areas:
- Link bandwidth utilisation
- Average end-to-end latency
- Interconnect and Edge capacity
- SFP compatibility with known GPU and TPU hardware
- Consideration for Smart NIC and DPU offload.
Just because your current network topology can run an AI workload or cope without AIOps doesn’t mean it will when your business starts deploying AI workloads at increasing pace.

Modify IT operations practices
AI comes from a world of software engineering backed by DevOps practices which might be at odds with your current IT service management approaches. Ensure cultural differences of AI workloads and tooling have been considered, such as:
- Continuous Integration with Continuous Deployment (CI/CD) pipelines for end-to-end infrastructure operation and deployment
- Governance via self-service approaches such as pull request (PR) and merge
- Infrastructure as Code (IaC) for self-documenting infrastructure, topologies and design validation
- Observability against proactive KPIs to replace reactive capacity management processes
- Automated remediation based on categorised risk tolerance levels of network change activity, removing humans from the loop where possible.
AI isn’t going to wait for an RFC before swamping a poorly-configured uplink with a deluge of elephant flows that exhaust your “deep” packet buffers. Controllerless networks are going to feel more strain, so software-defined networking (SDN) approaches should be considered to remove the need for high-touch human interaction in sustaining network operations.
Consolidate your current IT operations tooling
In our experience, it is not uncommon for clients to have a multitude of monitoring systems that have collected over the years. No business ever intends to have more than one, but you may have:
- Started a proof of concept (PoC) using PRTG for some of your network estate
- Implemented SolarWinds for your IT server and virtualisation equipment
- Spun up Cisco Prime Infrastructure for your mainly-Cisco network environment
- Added Tufin for your firewall and network security appliances
- Forgotten the small Juniper Space deployment for your Juniper SRX Firewall data centre edge.
- Purchasing yet another monitoring tool that introduces AIOps will not help here.
Now is a good time to reassess each monitoring tool from the perceived benefit against the actual benefit it gives you.
AIOps in conjunction with a comprehensive review of what you want your monitoring tools to add aligned to Observability pillars such of logs, metrics, and traces – and crucially aligning these to who is going to do what with each outcome – almost certainly will.

Provide AI-oriented training
Not every team member has to be—or will be—a full-fledged engineer, and that’s okay. There must, however, be at least a basic awareness of some of the nuances of how AI operates and some common pitfalls. For example:
- Think in terms of context and having the outcome you want in mind at all times
- Work with Large Language Models (LLM) context windows
- A PDF export of a NMS device inventory is likely to be bigger (in data storage terms) than a comparable CSV export – therefore use more context window “tokens” when fed into an AI prompt engine.
- Sanitise sensitive data from network configurations
- When using network vendor configurations across device families, the act of find-replacing a SNMP username/password might not be as easy as looking for “snmp-sever username…” due to syntax differences of the same configuration across vendors and even within similar devices from the same network vendor.
- Ensure you take extra time in sanitising sensitive data such as IP addresses, hostnames, SNMP username/passwords, PKI (SSH/SSL) certificate fingerprints and the like
- Consider AIOps an integral API that is central to your observability stack
- How will it process southbound data from network devices and element managers, and what protocol(s) will it utilise?
- Define the business logic that will help it understand the context of network deployment in your organisation
- Consider common fault scenarios and how these are codified into the AIOps tooling.
The key to both AIOps and AI workloads is ensuring the upfront work is taken to assess how these will change both technology and culture within your organisation before adding them to the potentially already-full pile of half-used monitoring tools on the organisational shelf.
How CACI can help
CACI understands the importance of data and streamlined processing. Our team possesses over 20 years of experience in every network engineering undertaking imaginable, from architecture, design and operations to managed networks and network automation. We are trusted by some of the UK’s most successful companies in finance, telco, utilities, government and public sector to innately understand their systems, culture and industries.
Talk to our Network Automation experts today and let us get you from network automation to NetDevOps to assure, run and manage the increasing velocity of AI workloads that are coming to network infrastructures on a wider scale.
Share this article